CTF部分
热身签到
十六进制和十进制解码
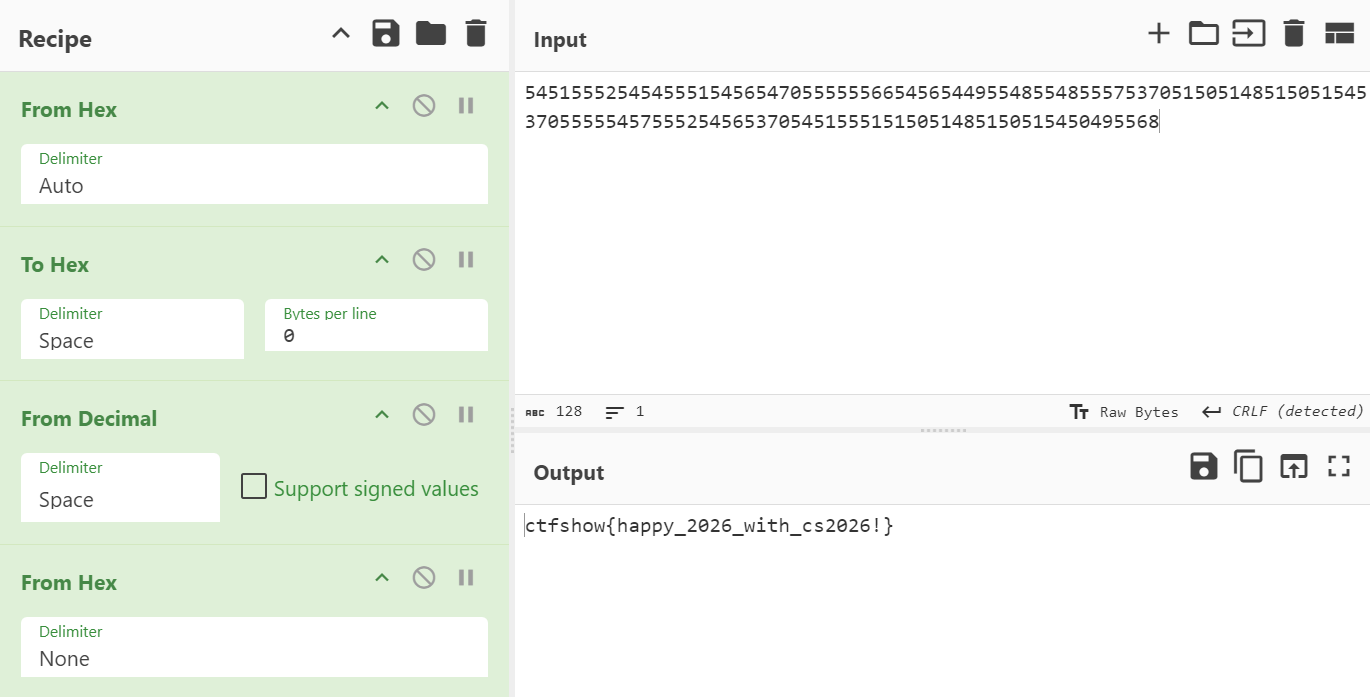
ctfshow{happy_2026_with_cs2026!}HappySong
wav有两种不同的频率的声音,转换成0和1
import numpy as np
import librosa
# --------------------------
# 读取音频
# --------------------------
filename = "drum_bits.wav"
y, sr = librosa.load(filename, sr=None)
# --------------------------
# 检测声音段
# --------------------------
frame_length = 2048
hop_length = 512
energy = np.array([
np.sum(np.abs(y[i:i+frame_length]**2))
for i in range(0, len(y), hop_length)
])
threshold = np.max(energy) * 0.1
is_sound = energy > threshold
sound_events = []
start = None
for i, val in enumerate(is_sound):
t = i * hop_length / sr
if val and start is None:
start = t
elif not val and start is not None:
end = t
sound_events.append((start, end))
start = None
if start is not None:
sound_events.append((start, len(y)/sr))
# --------------------------
# 提取每段主频
# --------------------------
def detect_pitch_segment(y_segment, sr, fmin=50, fmax=2000):
corr = np.correlate(y_segment, y_segment, mode='full')
corr = corr[len(corr)//2:]
d = np.diff(corr)
peaks = np.where(d > 0)[0]
if len(peaks) == 0:
return 0
start = peaks[0]
peak = np.argmax(corr[start:]) + start
if peak == 0:
return 0
freq = sr / peak
if freq < fmin or freq > fmax:
return 0
return freq
# --------------------------
# 转换成 . 和 - 并分组
# --------------------------
symbol_sequence = []
for start, end in sound_events:
start_sample = int(start * sr)
end_sample = int(end * sr)
segment = y[start_sample:end_sample]
freq = detect_pitch_segment(segment, sr)
if freq > 0:
symbol = '0' if freq > 500 else '1'
symbol_sequence.append(symbol)
# 每8个一组输出
for i in range(0, len(symbol_sequence), 8):
group = symbol_sequence[i:i+8]
print("".join(group),end=" ")得到的结果如下
10101010 01100011 01110100 01100110 01110011 01101000 01101111 01110111 01111011 01101010 01110101 01110011 01110100 01011111 01100001 01011111 01101110 01101001 01100011 01100101 01011111 01110011 01101111 01101110 01100111 01111101from bin 得到flag
ctfshow{just_a_nice_song}happyEmoji
一共有四种Emoji,周期分别是0,14/2,14/3,14。其对应关系为
0 = 0
14/2 = 1
14/3 = 3
14 = 2本题我的思路是先通过PS将所有的Emoji区域填充为红色,保存为red.png为后续坐标定位做准备

一直四种Emoji的周期固定,且GIF种一共有三个阶段,选取每个阶段中的固定帧作为每个阶段的代表,并截取出三种Emoji



通过截取到的emoji_0、emoji_1、emoji_2以及选取的每一阶段的代表,写一个图像识别代码
import cv2
import numpy as np
# --------------------------
# 配置参数
# --------------------------
MATCH_THRESHOLD = 0.90
ROWS = 24 # 总行数
COLS = 30 # 总列数
TEMPLATE_IMAGE_0 = "./emoji/emoji_0.png" # emoji0
TEMPLATE_IMAGE_1 = "./emoji/emoji_1.png" # emoji1
TEMPLATE_IMAGE_2 = "./emoji/emoji_2.png" # emoji2
for IMAGE_NUM in range(1, 5):
BIG_IMAGE = f"{IMAGE_NUM}.png"
OUTPUT_IMAGE = f"marked_{IMAGE_NUM}.png"
# --------------------------
# 读取图片
# --------------------------
img = cv2.imread(BIG_IMAGE)
marked = img.copy()
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
tpl_0 = cv2.imread(TEMPLATE_IMAGE_0)
tpl_gray_0 = cv2.cvtColor(tpl_0, cv2.COLOR_BGR2GRAY)
th_0, tw_0 = tpl_gray_0.shape
tpl_1 = cv2.imread(TEMPLATE_IMAGE_1)
tpl_gray_1 = cv2.cvtColor(tpl_1, cv2.COLOR_BGR2GRAY)
th_1, tw_1 = tpl_gray_1.shape
tpl_2 = cv2.imread(TEMPLATE_IMAGE_2)
tpl_gray_2 = cv2.cvtColor(tpl_2, cv2.COLOR_BGR2GRAY)
th_2, tw_2 = tpl_gray_2.shape
# --------------------------
# 从 red.png 提取中心
# --------------------------
red_img = cv2.imread("red.png")
lower_red = np.array([0, 0, 200])
upper_red = np.array([50, 50, 255])
mask = cv2.inRange(red_img, lower_red, upper_red)
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(mask, connectivity=8)
centers = []
for i in range(1, num_labels):
x, y, w, h, area = stats[i]
if w > h*1.5:
col_sum = np.sum(labels[y:y+h, x:x+w] == i, axis=0)
start = None
for xi, val in enumerate(col_sum):
if val > 0 and start is None:
start = xi
elif val == 0 and start is not None:
cx = x + (start + xi-1)//2
cy = int(centroids[i][1])
centers.append((cx, cy))
start = None
if start is not None:
cx = x + (start + w-1)//2
cy = int(centroids[i][1])
centers.append((cx, cy))
else:
cx, cy = int(centroids[i][0]), int(centroids[i][1])
centers.append((cx, cy))
centers.sort(key=lambda x: x[1])
result = []
for cx, cy in centers:
x0_0 = max(0, cx - tw_0//2 - 2)
y0_0 = max(0, cy - th_0//2 - 2)
x1_0 = min(img.shape[1], cx + tw_0//2 + 2)
y1_0 = min(img.shape[0], cy + th_0//2 + 2)
x0_1 = max(0, cx - tw_1//2 - 2)
y0_1 = max(0, cy - th_1//2 - 2)
x1_1 = min(img.shape[1], cx + tw_1//2 + 2)
y1_1 = min(img.shape[0], cy + th_1//2 + 2)
x0_2 = max(0, cx - tw_2//2 - 2)
y0_2 = max(0, cy - th_2//2 - 2)
x1_2 = min(img.shape[1], cx + tw_2//2 + 2)
y1_2 = min(img.shape[0], cy + th_2//2 + 2)
roi_0 = gray_img[y0_0:y1_0, x0_0:x1_0]
roi_1 = gray_img[y0_1:y1_1, x0_1:x1_1]
roi_2 = gray_img[y0_2:y1_2, x0_2:x1_2]
res_0 = cv2.matchTemplate(roi_0, tpl_gray_0, cv2.TM_CCOEFF_NORMED)
res_1 = cv2.matchTemplate(roi_1, tpl_gray_1, cv2.TM_CCOEFF_NORMED)
res_2 = cv2.matchTemplate(roi_2, tpl_gray_2, cv2.TM_CCOEFF_NORMED)
_, max_val_0, _, _ = cv2.minMaxLoc(res_0)
_, max_val_1, _, _ = cv2.minMaxLoc(res_1)
_, max_val_2, _, _ = cv2.minMaxLoc(res_2)
# 判定 emoji 类型
if max_val_0 >= MATCH_THRESHOLD:
label = 0
elif max_val_1 >= MATCH_THRESHOLD:
label = 1
elif max_val_2 >= MATCH_THRESHOLD:
label = 3
else:
label = 2
result.append(label)
# --------------------------
# 在图片上标注 0/1/2/3
# --------------------------
color = (0, 0, 255) if label == 0 else (0, 255, 0) if label == 1 else (255, 0, 0) if label == 2 else (255, 0, 255)
cv2.putText(marked, str(label), (cx - tw_0//4, cy + th_0//4), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
cv2.imwrite(OUTPUT_IMAGE, marked)
print(f"\n[+] Result for Image {IMAGE_NUM}:")
for r in range(ROWS):
row_str = "".join(str(x) for x in result[r*COLS:(r+1)*COLS])
print(row_str, end="")Emoji的中心坐标之间的间隔不是固定的,因此从red.png中的红色圆形确定每个Emoji中心点的位置。再将每个Emoji与存储的emoji_0、emoji_1、emoji_2进行相似度比较,对应标注0/1/2/3(4**4),得到的结果如下
[+] Result for Image 1:
001100100100001111101111101111333133333023333203132321322220111011111220112001013102020013101110102330331131330111231333101110111111111111110011111011133022202220103020322320322302111323231023120312012220033112311313331103331312113021201203111110111111111111111101111111303233222022322220023232221220130211033232130332130003331332102311212123132121000232130121111011111101100111010100110111322332200032133323332133303101132112122210111020102111231230202022311311311210103133111130011101110011011101100011111111321330203330303133333330031232100013221101130010201123011311113010131111101210113311313011101110110011111011111111111111222313322320102222332233222022122101112223112230010111102330132130213023302312111021110313
[+] Result for Image 2:
111111001111111111111111111110332120232032322230123223303223011033222003003312231321122311311033302120022111012322212030011111111111111111111111110110223202303222123332310330303213330022120333131003122112121011303203112213011121010221331131011101110011010101110101011101300332123330303330233023300333121013131123121012101220121010213113323311232021112330213110110011011101100111011101110101203330303132223020312331003231231101131113321323122112001001131111101313131012111321331220001101010111010101000011111011333030203300323232333300031323110112231012100210111100010131111123321230122111210033313301111111111111111111101111101010202312322220112213221022222213022113111023102111321131233212131130111103312130033311131331
[+] Result for Image 3:
111111001111111110111111101110322132232032322333222213230233012211222003033011233310311311111211302121332011221300100300111101110111111111111111111011132232203232223022323220001312001013330213030233000212222003003133003313200322122231131321101110101111101110111010111011232323331110031003100303031302002110000111300130103030321132320203321020202210232011121022111111101011101111111111111111201320031311030020022301001210210211302101303130322231110221021202201010113003123021231222111111101110111111111110111011022010130003011300030203121302321001213120312131313220021032120221103110311331132312221212101111111110111111101110011111132133230233222212232233333032101000301301233313311301011223102120100201221301012322322121
[+] Result for Image 4:
110110111111110111111111111111202233223222322222123312300220323211031023033333130003021212133311201222033213002103110231110000000000000000000000000000000000000000000000000000000000220000000000000000000000000000130000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000再写一个按一列4个,从左到右从上到下读取的代码
raw_data = "……"
lines = [raw_data[i:i+30] for i in range(0, len(raw_data), 30)]
group_size = 4
def process_lines(lines):
n = len(lines)
for i in range(0, n, group_size):
group = lines[i:i+group_size]
if len(group) < group_size:
continue
num_cols = len(group[0])
for col in range(num_cols):
col_bits = "".join(group[row][col] for row in range(group_size))
# 4进制转为十进制
decimal_value = int(col_bits, 4)
# 将十进制值转换为字符
char = chr(decimal_value)
print(char, end="")
process_lines(lines)得到的结果如下
54uQ54u46K+077yaCuS7luaYr+acgOW5uOi/kOeahOWKqOeJqe+8jArlm6DkuLrku5bmnInkuobmnIDlpb3nmoTmnIvlj4vjgIIK5aW55rip5p+U77yM5YOP5aSp5LiK55qE5LqR5py177yMCuWluee+juS4ve+8jOWDj+mbquadvueahOmcsuePoO+8jArlpbnmuIXmvojvvIzlg4/lsbHkuIrnmoTmuqrmtYHvvIwK5aW56IGq5oWn77yM6K6p6Ieq6K+p6IGq5piO55qE5LuW5om+5LiN5Yiw6YCC5b2T55qE6K+N5rGH5b2i5a6544CCCuS7luaKiuWlueeahOWQjeWtl+WGmei/m+W9qeiZue+8jArmsonpu5jnmoTpm4Dot4Ppga7olL3kuoblpKnnqbrjgIIKY3Rmc2hvd3s2QTVDN0RFM0VCN0M1MzU4NjhFQzdFN0Y4QTM1ODlCMjkxNUFGQjZFMjdBREY4OEI0OUYwOEMwNkI2RjU2MjU0fQrpmpDnp5jnmoTml5for63vvIzmmK/ku5blubjnpo/nmoTlrqPoqIDjgIIKBase64解码
狐狸说:
他是最幸运的动物,
因为他有了最好的朋友。
她温柔,像天上的云朵,
她美丽,像雪松的露珠,
她清澈,像山上的溪流,
她聪慧,让自诩聪明的他找不到适当的词汇形容。
他把她的名字写进彩虹,
沉默的雀跃遮蔽了天空。
ctfshow{6A5C7DE3EB7C535868EC7E7F8A3589B2915AFB6E27ADF88B49F08C06B6F56254}
隐秘的旗语,是他幸福的宣言。得到Flag
ctfshow{6A5C7DE3EB7C535868EC7E7F8A3589B2915AFB6E27ADF88B49F08C06B6F56254}SafePIN
先按照SYMBOL_SEQUENCE设置的按键音进行录制,写代码识别音频的高频和低频,多次取众数
import numpy as np
from scipy.io import wavfile
from collections import Counter
wav_path = 'origin.wav'
fs, data = wavfile.read(wav_path)
if data.ndim > 1:
data = data.mean(axis=1)
data = data / np.max(np.abs(data))
FRAME = int(0.025 * fs)
HOP = int(0.010 * fs)
THRESH_FACTOR = 0.3
def energy(x):
return np.mean(x**2)
n_frames = (len(data) - FRAME) // HOP + 1
eng = np.array([energy(data[i*HOP:i*HOP+FRAME]) for i in range(n_frames)])
th = THRESH_FACTOR * (np.percentile(eng, 98) - np.percentile(eng, 2)) + np.percentile(eng, 2)
onsets, in_seg = [], False
for i, e in enumerate(eng):
if not in_seg and e > th:
onsets.append(i)
in_seg = True
elif in_seg and e < th:
in_seg = False
def two_peaks(sig, fs):
N = len(sig)
w = np.hanning(N)
spec = np.fft.rfft(sig * w)
freq = np.fft.rfftfreq(N, 1/fs)
mag = np.abs(spec)
mask = (freq > 500) & (freq < 1600)
freq, mag = freq[mask], mag[mask]
idx = np.argpartition(mag, -2)[-2:]
idx = idx[np.argsort(mag[idx])][::-1]
f1, f2 = freq[idx]
return sorted([f1, f2])
SYMBOL_SEQUENCE = [
'0','0','0','0','0','0','*',
'1','1','1','1','1','1','*',
'2','2','2','2','2','2','*',
'3','3','3','3','3','3','*',
'4','4','4','4','4','4','*',
'5','5','5','5','5','5','*',
'6','6','6','6','6','6','*',
'7','7','7','7','7','7','*',
'8','8','8','8','8','8','*',
'9','9','9','9','9','9','*',
'1','1','1','1','1','1','#',
]
buckets = {sym: [] for sym in set(SYMBOL_SEQUENCE)}
for k, start in enumerate(onsets):
if k >= len(SYMBOL_SEQUENCE):
break
t0 = max(0, start*HOP - int(0.02*fs))
t1 = min(len(data), (start+35)*HOP)
seg = data[t0:t1]
lf, hf = two_peaks(seg, fs)
print(f'段{k:>2} 符号={SYMBOL_SEQUENCE[k]} 低频={lf:6.1f} Hz 高频={hf:6.1f} Hz')
buckets[SYMBOL_SEQUENCE[k]].append((lf, hf))
def mode_xy(points):
lf_all, hf_all = zip(*points)
lf_cnt = Counter(lf_all)
hf_cnt = Counter(hf_all)
return lf_cnt.most_common(1)[0][0], hf_cnt.most_common(1)[0][0]
final_table = {}
for sym, pts in buckets.items():
if not pts:
continue
lf, hf = mode_xy(pts)
final_table[sym] = (lf, hf)
ORDER = ['0','1','2','3','4','5','6','7','8','9','*','#']
print('—— 频率对照表 ——')
for sym in ORDER:
if sym in final_table:
lf, hf = final_table[sym]
print(f'({lf:6.1f}, {hf:6.1f}), #{sym:>2}')得到码表
(1073.0, 1075.7), # 0
(1032.4, 1037.8), # 1
(1159.5, 1162.2), # 2
(1202.7, 1205.4), # 3
(1145.9, 1148.6), # 4
(1213.5, 1216.2), # 5
(1240.5, 1243.2), # 6
(1110.8, 1113.5), # 7
(1108.1, 1108.1), # 8
(1294.6, 1297.3), # 9
(1286.5, 1289.2), # *
(1283.8, 1286.5), # #对下载的record.wav进行解码
import numpy as np
from scipy.io import wavfile
# ======= 自定义频率表=======
FREQ_TABLE = [
(1073.0, 1075.7), # 0
(1032.4, 1037.8), # 1
(1159.5, 1162.2), # 2
(1202.7, 1205.4), # 3
(1145.9, 1148.6), # 4
(1213.5, 1216.2), # 5
(1240.5, 1243.2), # 6
(1110.8, 1113.5), # 7
(1108.1, 1108.1), # 8
(1294.6, 1297.3), # 9
(1286.5, 1289.2), # *
(1283.8, 1286.5), # #
]
SYMBOLS = ['0','1','2','3','4','5','6','7','8','9','*','#']
# ============================================
wav_path = 'record.wav'
fs, data = wavfile.read(wav_path)
if data.ndim > 1:
data = data.mean(axis=1)
data = data / np.max(np.abs(data))
FRAME = int(0.025 * fs) # 窗长 25 ms
HOP = int(0.010 * fs) # 帧移 10 ms
THRESH_FACTOR = 0.2 # 能量阈值系数
TOL = 4.0 # 双门限容差 Hz
def energy(x):
return np.mean(x**2)
n_frames = (len(data) - FRAME) // HOP + 1
eng = np.array([energy(data[i*HOP:i*HOP+FRAME]) for i in range(n_frames)])
th = THRESH_FACTOR * (np.percentile(eng, 98) - np.percentile(eng, 2)) + np.percentile(eng, 2)
onsets, in_seg = [], False
for i, e in enumerate(eng):
if not in_seg and e > th:
onsets.append(i)
in_seg = True
elif in_seg and e < th:
in_seg = False
if onsets:
merged = [onsets[0]]
for t in onsets[1:]:
if (t - merged[-1]) * HOP / fs > 0.08:
merged.append(t)
onsets = merged
def two_peaks(sig, fs):
N = len(sig)
w = np.hanning(N)
spec = np.fft.rfft(sig * w)
freq = np.fft.rfftfreq(N, 1/fs)
mag = np.abs(spec)
# 只留 500–1600 Hz
mask = (freq > 500) & (freq < 1600)
freq, mag = freq[mask], mag[mask]
# 取最高两条峰
if len(mag) < 2:
return None, None
idx = np.argpartition(mag, -2)[-2:]
idx = idx[np.argsort(mag[idx])][::-1]
f1, f2 = freq[idx]
return sorted([f1, f2])
def match_peak(lf, hf, table, tol=4.0):
cand = []
for idx, (l, h) in enumerate(table):
if abs(lf - l) < tol and abs(hf - h) < tol:
cand.append((abs(lf - l) + abs(hf - h), idx))
if not cand:
return None
return min(cand)[1]
decoded = []
for start in onsets:
t0 = max(0, start*HOP - int(0.02*fs))
t1 = min(len(data), (start+35)*HOP)
seg = data[t0:t1]
lf, hf = two_peaks(seg, fs)
if lf is None or hf is None:
decoded.append('?')
print(f'帧{start:3d} 未检出有效双峰')
continue
idx = match_peak(lf, hf, FREQ_TABLE, tol=TOL)
if idx is None:
decoded.append('?')
print(f'帧{start:3d} 实测峰值= {lf:7.1f} Hz , {hf:7.1f} Hz → 无匹配')
else:
decoded.append(SYMBOLS[idx])
print(f'帧{start:3d} 实测峰值= {lf:7.1f} Hz , {hf:7.1f} Hz → 符号 {SYMBOLS[idx]}')
print('\n解码结果:', ''.join(decoded))帧 21 实测峰值= 1159.5 Hz , 1162.2 Hz → 符号 2
帧 37 实测峰值= 1294.6 Hz , 1297.3 Hz → 符号 9
帧 54 实测峰值= 1286.5 Hz , 1291.9 Hz → 符号 *
帧 70 实测峰值= 1145.9 Hz , 1148.6 Hz → 符号 4
帧 88 实测峰值= 1143.2 Hz , 1148.6 Hz → 符号 4
帧105 实测峰值= 1110.8 Hz , 1113.5 Hz → 符号 7
帧121 实测峰值= 1240.5 Hz , 1243.2 Hz → 符号 6
帧137 实测峰值= 1108.1 Hz , 1110.8 Hz → 符号 8
帧153 实测峰值= 1213.5 Hz , 1216.2 Hz → 符号 5
帧170 实测峰值= 1283.8 Hz , 1286.5 Hz → 符号 #
帧186 实测峰值= 1282.4 Hz , 1285.2 Hz → 符号 #
解码结果: 29*447685##