Misc
hiden
题目附件有一个wav文件,初步查看发现没有异常,所以从60=()+().txt文件入手。通过编码识别出为ROT47,根据感觉或者文件名可以知道还需要进行ROT13或者Caesar偏移13都可以,解码后得到wav加密代码,写出解密代码。
import wave
with wave.open("hiden.wav", "rb") as f:
attrib = f.getparams()
wav_data = bytearray(f.readframes(-1))
extracted_data = []
for i in range(0, len(wav_data), 4):
if i < len(wav_data):
extracted_data.append(wav_data[i])
extracted_bytes = bytes(extracted_data)
if len(extracted_bytes) >= 3:
length_prefix = int.from_bytes(extracted_bytes[:3], 'little')
text_data = extracted_bytes[3:3+length_prefix]
flag_text = text_data.decode('utf-8')
print(flag_text)
else:
print("Wrong")得到flag
ok,now you find me,so the flag give you
DASCTF{12jkl-456m78-90n1234}Check in
首先在附件压缩包中发现一串base,解码得到一串字符串
5unVpeVXGvjFah base58---->
Welcome2GZtxt文件是流量包的十六进制,先导出为流量包,但是发现流量包损坏,这里用在线网站或者NetA都可以进行修复。打开压缩包发现很多SMB流量,并且原先的txt中存在空格和\x00,初步分析止步于此。
后面放出了hint,txt存在第二层面纱,重新对txt文档进行分析,先将txt文档以utf-8编码打开并保存,一开始考虑的是零宽,但是未解出。尝试wbStego4open,输入密码得到一个txt文件,查询后发现是tls.log文件。
这里可以使用Wireshark,在菜单栏中找到编辑,并在Protocols中找到tls,并导入log文件
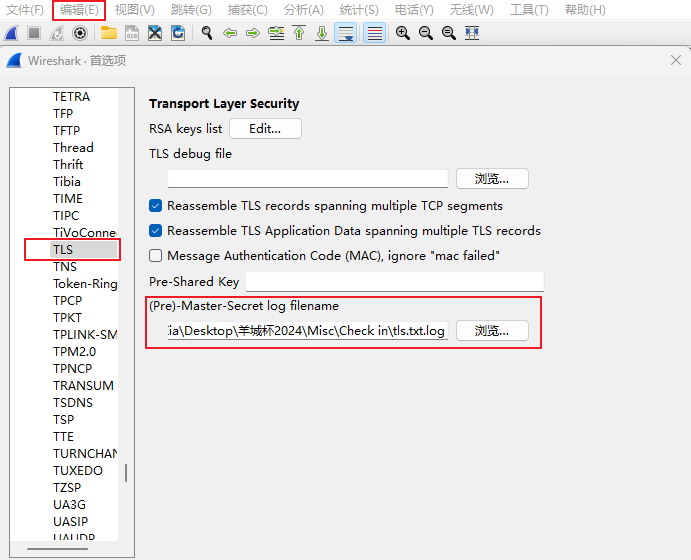
导入后在流33发现post传的flag.gif,将gif导出

提取GIF帧间隔
['30', '230', '30', '230', '30', '230', '30', '230', '30', '230', '30', '230', '230', '230', '230', '230', '30', '30', '230', '230', '30', '30', '30', '30', '30', '230', '230', '230', '30', '230', '230', '230', '30', '230', '30', '30', '230', '230', '230', '30', '30', '230', '30', '230', '230', '230', '230', '230', '30', '30', '230', '230', '30', '30', '30', '230', '30', '230', '30', '230', '30', '230', '30', '30']发现只有30和230两种,分别转化为0和1,再转为字符,得到flag
0101010101011111001100000111011101001110010111110011000101010100
U_0wN_1T1z_misc
题目和hint如下
天地玄黄,宇宙洪荒;日月盈昃,辰宿列张;万物芸芸,息息相关;是以十二岁而行二十八宿,其间奥妙,待探寻,显真章。
若女可为11,可为1124......觜可为91,亦可为725......如此往复,周而复始。
祈解其秘:[43,101,55,16,16,1017,28,812,824,43,55,226,101,55,55,415,1017,1027,28,28,617,824,28,812,1027,16,101,16,55,1027,1017,28,16]
hint:十二支藏二十八星宿,细看二者关联,数字不一定只是数字本身~这里我们先看十二地支和二十八星宿图结合图片来解释原理

数字由两部分组成:
前半部分代表的是十二地支偏移量,从子开始为1,顺时针计数。
后半部分代表的是二十八星宿偏移量,从相应地支最右边开始为1,逆时针计数。
明白这个过后就能理解为什么女可为11,可为1124,觜可为91,亦可为725了。对密文进行解密:
[心,胃,心,奎,奎,心,奎,心,胃,心,心,心,胃,心,心,胃,心,奎,奎,奎,奎,胃,奎,心,奎,奎,胃,奎,心,奎,心,奎,奎]可以发现里面只有心,胃,奎,分别转为0,1,2
010220201000100102222120221202022观察发现只有1可能作为分隔符,在线网站解码会显示错误,这里用CyberChef,得到压缩包密码

E@SI1Y!解压得到一个未命名文件和hint.jpg,图片为天琴座(lyra),参考 ISCC2024的一道题目通过lyra进行解码,未命名文件修改后缀名为flag.lyra
这里试了很多办法也没能配置好环境,解题思路和ISCC的大体相似,将得到的wav进行语音转文字得到社会主义核心价值观编码,进行解码得到flag
miaoro
附件为一个流量包,通过分析发现流量包的数据流中存在zip文件

先from dumphex将十六进制整理出来,再进行reverse,得到zip

导出发现需要密码,并且压缩包内的只是flag2,说明还有flag1。
分析流量包发现shiro特征,直接用最后一个流的值,key是1234567890abcdef,算法是CBC,AES解密后得到flag1

DASCTF{B916CFEB-C40F-45D6-A7BC-flag2需要密码进行解压,我们在zip流附近开始查找,在流10的GWHT中找到密码


echo Th15_11111111s_pP@sssssw000rd!!!>pass.txt解压后得到一张jpg图片,发现可能宽度不对,crc检验证实了想法,在010中进行修改

得到完整的图(猫猫可爱捏(●'◡'●)

搜索发现猫猫字体对应的字母表

对应解码得到flag
EBOFDELQDIAA}综上所述
DASCTF{B916CFEB-C40F-45D6-A7BC-EBOFDELQDIAA}不一样的数据库_2
附件为一个加密的压缩包,打开010在末尾发现信息

进行爆破,先尝试纯数字,得到密码

解压后得到一个残缺二维码和kdbx文件,先对二维码补全进行解码,得到以下信息
NRF@WQUKTQ12345&WWWF@WWWFX#WWQXNWXNU但是后面尝试后发现是不对的,根据题目描述需要注意文件名13.jpg,所以进行ROT13,得到正确的密码
AES@JDHXGD12345&JJJS@JJJSK#JJDKAJKAHkdbx文件使用KeePass打开,在文件中发现AES密文和key

解码得到flag

DASCTF[snsnndjahenanheanjjskk12235)so much
附件为一个ad1磁盘文件,010查看末尾发现信息

将文件名进行base64解码也能得到信息
c2hpZnQh --->base64
shift!结合得到的信息可以找到正确的key
!@#$%^&在FTK Imager中挂载磁盘文件,并提取内容,总共发现345个crypto文件,并且关注修改日期可以发现末尾只为19和20。并且345可以被8整除,这里我们对照时间进行01转化,并将二进制转成字符串

import os
list = ['']*344
i = 0
for j in range(344):
list[j] = os.path.getmtime(str(j)+'.crypto')
flag = ''
for i in range(344):
if(str(list[i]) == '1628151585.73009'):
flag += '0'
else:
flag += '1'
tmp = ''
for k in range(len(flag)):
tmp += flag[k]
if len(tmp) == 8:
print(chr(int(tmp,2)),end='')
tmp = ''
# the_key_is_700229c053b4ebbcf1a3cc37c389c4fa得到key,使用
Encrypto对创建时间不同的两个文件进行解密,分别得到一半flag,组合得到最终flag
DASCTF{85235bd803c2a0662b771396bce9968f}数据安全
data-analy1
import pandas as pd
import re
patterns = {
'编号': re.compile(r'^([1-9]\d{0,3}|10005)$'),
'手机号码': re.compile(r'^(734|735|736|737|738|739|747|748|750|751|752|757|758|759|772|778|782|783|784|787|788|795|798|730|731|732|740|745|746|755|756|766|767|771|775|776|785|786|796|733|749|753|773|774|777|780|781|789|790|791|793|799)[0-9]{8}$'),
'身份证号': re.compile(r'^\d{17}[\dX]$'),
'姓名': re.compile(r'^[\u4e00-\u9fa5]+$'),
'密码': re.compile(r'^[a-f0-9]{32}$'),
'性别': re.compile(r'^(男|女)$'),
'出生日期': re.compile(r'^(\d{4})(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])$'),
'用户名': re.compile(r'^[0-9A-Za-z]+$')
}
def classify_value(value):
if isinstance(value, str):
for col, pattern in patterns.items():
if pattern.match(value):
if col == '姓名' and value in ['男', '女']:
continue
return col, value
return None, None
def process_row(row):
result = {col: '' for col in ordered_columns}
for value in row:
col, val = classify_value(value)
if col:
result[col] = val
return pd.Series(result)
input_csv = 'person_data.csv'
df = pd.read_csv(input_csv, header=None)
ordered_columns = ['编号', '用户名', '密码', '姓名', '性别', '出生日期', '身份证号', '手机号码']
new_df = df.apply(process_row, axis=1)
new_df = new_df.reindex(columns=ordered_columns)
new_df.fillna('', inplace=True)
output_csv = 'data.csv'
new_df.to_csv(output_csv, index=False)
print(f"数据已恢复并保存到 {output_csv}"导出的csv有一丢丢小问题,但是检测能过就没修了
data-analy2
通过流量包提取出信息,先将信息整理正csv格式的文件
import csv
import json
def read_data_from_txt(txt_file):
with open(txt_file, 'r', encoding='utf-8') as file:
lines = file.readlines()
data = [json.loads(line.strip()) for line in lines]
return data
def write_data_to_csv(data, csv_file):
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=["username", "name", "sex", "birth", "idcard", "phone"])
writer.writeheader()
writer.writerows(data)
txt_file = 'data.txt'
csv_file = 'data.csv'
data = read_data_from_txt(txt_file)
write_data_to_csv(data, csv_file)
print(f'数据已保存到 {csv_file}')再根据题目要求整理出需要的信息
import pandas as pd
import re
VALID_PREFIXES = {
'734', '735', '736', '737', '738', '739', '747', '748', '750', '751',
'752', '757', '758', '759', '772', '778', '782', '783', '784', '787',
'788', '795', '798', '730', '731', '732', '740', '745', '746', '755',
'756', '766', '767', '771', '775', '776', '785', '786', '796', '733',
'749', '753', '773', '774', '777', '780', '781', '789', '790', '791',
'793', '799'
}
def validate_username(username):
return bool(re.match(r'^[a-zA-Z0-9]+$', username))
def validate_name(name):
return bool(re.match(r'^[\u4e00-\u9fff]+$', name))
def validate_sex(sex, idcard):
if sex not in ['男', '女']:
return False
gender_digit = int(idcard[-2])
expected_sex = '男' if gender_digit % 2 == 1 else '女'
return sex == expected_sex
def validate_birth(birth, idcard):
birth = str(birth)
if not re.match(r'^\d{8}$', birth):
return False
idcard_birth = idcard[6:14]
return birth == idcard_birth
def validate_idcard(idcard):
if len(idcard) != 18 or not re.match(r'^\d{17}(\d|X)$', idcard):
return False
weights = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
check_code = '10X98765432'
weighted_sum = sum(int(idcard[i]) * weights[i] for i in range(17))
remainder = weighted_sum % 11
expected_check_digit = check_code[remainder]
return idcard[-1] == expected_check_digit
def validate_phone(phone):
prefix = phone[:3]
return prefix in VALID_PREFIXES
df = pd.read_csv('data.csv', skiprows=1, header=None, names=['username', 'name', 'sex', 'birth', 'idcard', 'phone'])
invalid_records = []
for index, row in df.iterrows():
username = str(row['username']).strip()
name = str(row['name']).strip()
sex = str(row['sex']).strip()
birth = str(row['birth']).strip()
idcard = str(row['idcard']).strip()
phone = str(row['phone']).strip()
valid_username = validate_username(username)
valid_name = validate_name(name)
valid_sex = validate_sex(sex, idcard)
valid_birth = validate_birth(birth, idcard)
valid_idcard = validate_idcard(idcard)
valid_phone = validate_phone(phone)
if not (valid_username and valid_name and valid_sex and valid_birth and valid_idcard and valid_phone):
invalid_records.append(row)
invalid_df = pd.DataFrame(invalid_records)
invalid_df.to_csv('wrong.csv', index=False)data-analy3
解压后发现用户信息存储在error.log中,先对error.log进行提取处理
import csv
input_log_file = 'error.log'
output_csv_file = 'output.csv'
EXCLUDED_FIELDS = ['\xe6\x82\xa8\xe8\xbe\x93\xe5\x85\xa5\xe7\x9a\x84\xe7\x94\xa8\xe6\x88\xb7\xe5\x90\x8d\xe4\xb8\x8d\xe5\xad\x98\xe5\x9c\xa8\xef\xbc\x81']
def extract_username_password(lines):
extracted_lines = []
total_lines = len(lines)
for i in range(total_lines):
line = lines[i]
if 'username' in line:
start_index = line.find('username')
extracted_line = line[start_index:].strip()
seventh_line_index = i + 6
if seventh_line_index < total_lines:
seventh_line = lines[seventh_line_index].strip()
if any(field in seventh_line for field in EXCLUDED_FIELDS):
continue
keyword = "(data-HEAP): "
if keyword in seventh_line:
try:
password_content = seventh_line.split(keyword, 1)[1].strip()
if ": " in password_content:
password_content = password_content.split(": ", 1)[1].strip()
password_content = password_content.replace('\\n', '')
extracted_line += '&password=' + password_content
extracted_lines.append(extracted_line)
except IndexError:
continue
return extracted_lines
with open(input_log_file, 'r') as log_file:
lines = log_file.readlines()
extracted_lines = extract_username_password(lines)
with open(output_csv_file, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
for extracted_line in extracted_lines:
csv_writer.writerow([extracted_line])
print(f"提取的内容已保存到 {output_csv_file}")再针对name的url编码,以及特定列顺序进行整理
import csv
import urllib.parse
def process_data(input_file, output_file):
data_list = []
with open(input_file, 'r') as infile:
for line in infile:
params = line.strip().split('&')
data_dict = {}
for param in params:
key, value = param.split('=')
if key == 'name':
value = urllib.parse.unquote(value)
data_dict[key] = value
data_list.append({
'username': data_dict.get('username', ''),
'password': data_dict.get('password', ''),
'name': data_dict.get('name', ''),
'idcard': data_dict.get('idcard', ''),
'phone': data_dict.get('phone', '')
})
with open(output_file, 'w', newline='', encoding='utf-8') as outfile:
writer = csv.DictWriter(outfile, fieldnames=['username', 'password', 'name', 'idcard', 'phone'])
writer.writeheader()
writer.writerows(data_list)
input_file = 'output.csv'
output_file = 'sorted_data.csv'
process_data(input_file, output_file)筛选出符合要求的数据
import pandas as pd
import re
VALID_PREFIXES = {
'734', '735', '736', '737', '738', '739', '747', '748', '750', '751',
'752', '757', '758', '759', '772', '778', '782', '783', '784', '787',
'788', '795', '798', '730', '731', '732', '740', '745', '746', '755',
'756', '766', '767', '771', '775', '776', '785', '786', '796', '733',
'749', '753', '773', '774', '777', '780', '781', '789', '790', '791',
'793', '799'
}
def validate_username(username):
return bool(re.match(r'^[a-zA-Z0-9]+$', username))
def validate_name(name):
return bool(re.match(r'^[\u4e00-\u9fff]+$', name))
def validate_idcard(idcard):
if len(idcard) != 18 or not re.match(r'^\d{17}(\d|X)$', idcard):
return False
weights = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
check_code = '10X98765432'
weighted_sum = sum(int(idcard[i]) * weights[i] for i in range(17))
remainder = weighted_sum % 11
expected_check_digit = check_code[remainder]
return idcard[-1] == expected_check_digit
def validate_phone(phone):
prefix = phone[:3]
return prefix in VALID_PREFIXES
df = pd.read_csv('sorted_data.csv', skiprows=1, header=None, names=['username', 'password','name', 'idcard', 'phone'])
invalid_records = []
for index, row in df.iterrows():
username = str(row['username']).strip()
name = str(row['name']).strip()
idcard = str(row['idcard']).strip()
phone = str(row['phone']).strip()
valid_username = validate_username(username)
valid_name = validate_name(name)
valid_idcard = validate_idcard(idcard)
valid_phone = validate_phone(phone)
if (valid_username and valid_name and valid_idcard and valid_phone):
invalid_records.append(row)
invalid_df = pd.DataFrame(invalid_records)
invalid_df.to_csv('right.csv', index=False)最后进行脱敏处理
import csv
import hashlib
def md5_hash(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()
def mask_username(username):
if len(username) <= 2:
return username[0] + '*'
return username[0] + '*' * (len(username) - 2) + username[-1]
def mask_password(password):
return md5_hash(password)
def mask_name(name):
if len(name) == 2:
return name[0] + '*'
elif len(name) >= 3:
return name[0] + '*' * (len(name) - 2) + name[-1]
return name
def mask_idcard(idcard):
if len(idcard) == 18:
return '*' * 6 + idcard[6:10] + '*' * 8
return idcard
def mask_phone(phone):
if len(phone) == 11:
return phone[:3] + '****' + phone[-4:]
return phone
def process_data(input_file, output_file):
data_list = []
with open(input_file, 'r', encoding='utf-8') as infile:
reader = csv.DictReader(infile)
for row in reader:
processed_data = {
'username': mask_username(row['username']),
'password': mask_password(row['password']),
'name': mask_name(row['name']),
'idcard': mask_idcard(row['idcard']),
'phone': mask_phone(row['phone'])
}
data_list.append(processed_data)
with open(output_file, 'w', newline='', encoding='utf-8') as outfile:
fieldnames = ['username', 'password', 'name', 'idcard', 'phone']
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data_list)
input_file = 'right.csv'
output_file = 'end.csv'
process_data(input_file, output_file)